Deep Convolutional Neural Networks (DCNNs) have made surprising progress in synthesising high-quality and coherent images. The best performing neural network architectures in the generative domain are the class of Generative Adversarial Networks (GANs). These networks have been applied in many different scenarios: domain transfer of images, e.g. going from sunny to winter environments; generating images from text descriptions; using computer generated data to train neural networks for real world settings; and many other domains. GANs also lend themselves extremely well to fun and playful uses, some of which have really captured the internet’s attention:
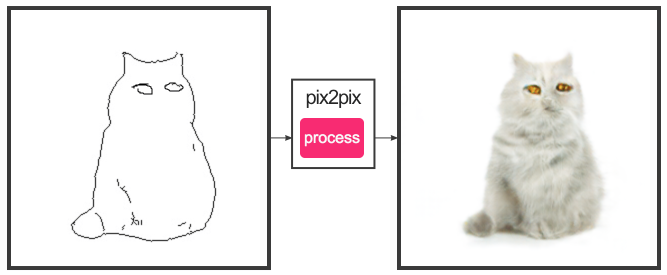 |
|---|
| Going from sketch of a cat to a cat using pix2pix |
But how do we apply these techniques to create something more than just a throwaway demo? At our lab, we have a project around exploring the use of artificial intelligence (AI) in creating interactive experiences for online and in-gallery art collections. We believe that deep neural networks have immense potential to create novel and relevant experiences around artworks, because these techniques allow us to understand, manipulate, and generate visual content like never before. As our first experiment within the larger project, we’ve taken these techniques and developed a generative experiment that we are calling the Marble Mirror.
Marble Mirror is a real-time interactive system that acts as a kind of a generative funhouse mirror. The system is made up of two parts: a facial landmark detector and a generative adversarial network. The detector works to extract facial expressions from video frames, these are then passed as a simple black and white sketch to a GAN, which renders the expressions as a marble sculpture. Here is a animated gif of the system in action (gif is rendered at same frame rate as real-time performance):
 |
|---|
| System in action |
The motivation behind the idea came from thinking about the current, predominantly passive, visiting experience of a gallery exhibition. As a visitor, you normally walk around the gallery space, look at the works from a distance, admire the artistry, but rarely do you have an opportunity to interact with the works. But what if you could see some works come to life? For this experiment, imagine the setting to be an in-gallery exhibition of ancient Roman sculptures, where the Marble Mirror is set up on a large screen. The interactive experience would let a passer by see themselves rendered as a sculpture they’ve seen in the exhibition. It would let them explore how changing their facial expressions takes them from one sculpture to another, see which sculpture their face structure matches, and just have fun by making funny faces. Our aim is to provide an experience in-addition to the exhibition, something that is contextual and relevant to the art on display.
Overview of the system
How do we go from a picture of a face to a marble sculpture with the same expressions? Training a generative network to do this directly would be an impractical approach, so we addressed this by performing an intermediate step of facial landmark detection. This allows us to extract the main facial landmarks (jawline, eyes, eyebrows, nose, and mouth) from an image, enough to capture the facial expression of the person. These extracted expressions are drawn as a simple sketch, and used as the input to the GAN.
The high-level breakdown of the system is:
- Input from webcam ->
- Extract facial landmarks ->
- Draw a simple sketch of expressions ->
- Generate marble sculpture and display result
We collected a diverse dataset of marble bust images ranging in expressions, gender, and facial feature proportions. It was important to make sure that we had marble busts representing all types of expressions (smiling marble busts are very difficult to find), because the neural network can only coherently synthesise expressions and facial structures it has seen before. The craftsmanship of the sculptures was to such a high degree that the facial landmark extraction performed extremely well on sculpture images. This allowed us to automate the creation of the input/output pairs required for training a GAN.
 |
|---|
| Extracting facial landmarks from sculpture images for training |
We used the pix2pix GAN architecture with PyTorch for training the network. The training process required a lot of experimentation with the training dataset and network-parameters before the we achieved visually pleasing results.
About the Author
 |
Dilpreet is a member of the SensiLab Creative AI team and develops applications using deep learning for artistic and aesthetic expression. Follow Dilpreet on twitter |
|---|---|